Unpaywall Journals - possibly the most interesting thing to happen this year in library subscription land.
Wed Nov 6, 2019
660 Words
Heather and Jason from https://ourresearch.org/ have just released a preview of their new tool - unpaywall journals. You can have a look at the preview of this tool now - Unpaywall Journals.
They previewed this two weeks ago at FORCE2019 and have clearly gone through a ton of work to get the tool the state it is in todday, so big congraatulations to them on the product release.
For those of you not in the know they have a long track record of building useful open infrastructure in the scholarly communications spaace. The product that they hvae built to date that has probably had the biggest impact is Unpaywall which maps over 24M scholarly articles to open access versions of those articles. By using data from this tool they have recently been able to make what they believe are high resolution projections of the growth of different forms of open access for most journals in the world - paper here - bioarxive piwower - Google Search.
If you were a librarian, and you knew how much of the a journal you are currently subscribing too were to become open access over the next five years, and furthermore you could match that data with the specific usage of that journal by your patrons, along with estimating how much it would cost you to get some of that content via inter library loans, then that might make it easy for you to decide whether to keep subscribing to that journal in the future. Now imagine you could do that in one moment for your entire collection, and have a tool that automatically modelled different scenarios for you. That’s what unpaywall journals is aiming to be.
The tool released for preview this week has A LOT of functionality in it, but I’ll just show two screen shots that I grabbed that nicely summarise the gist of what is going on here.
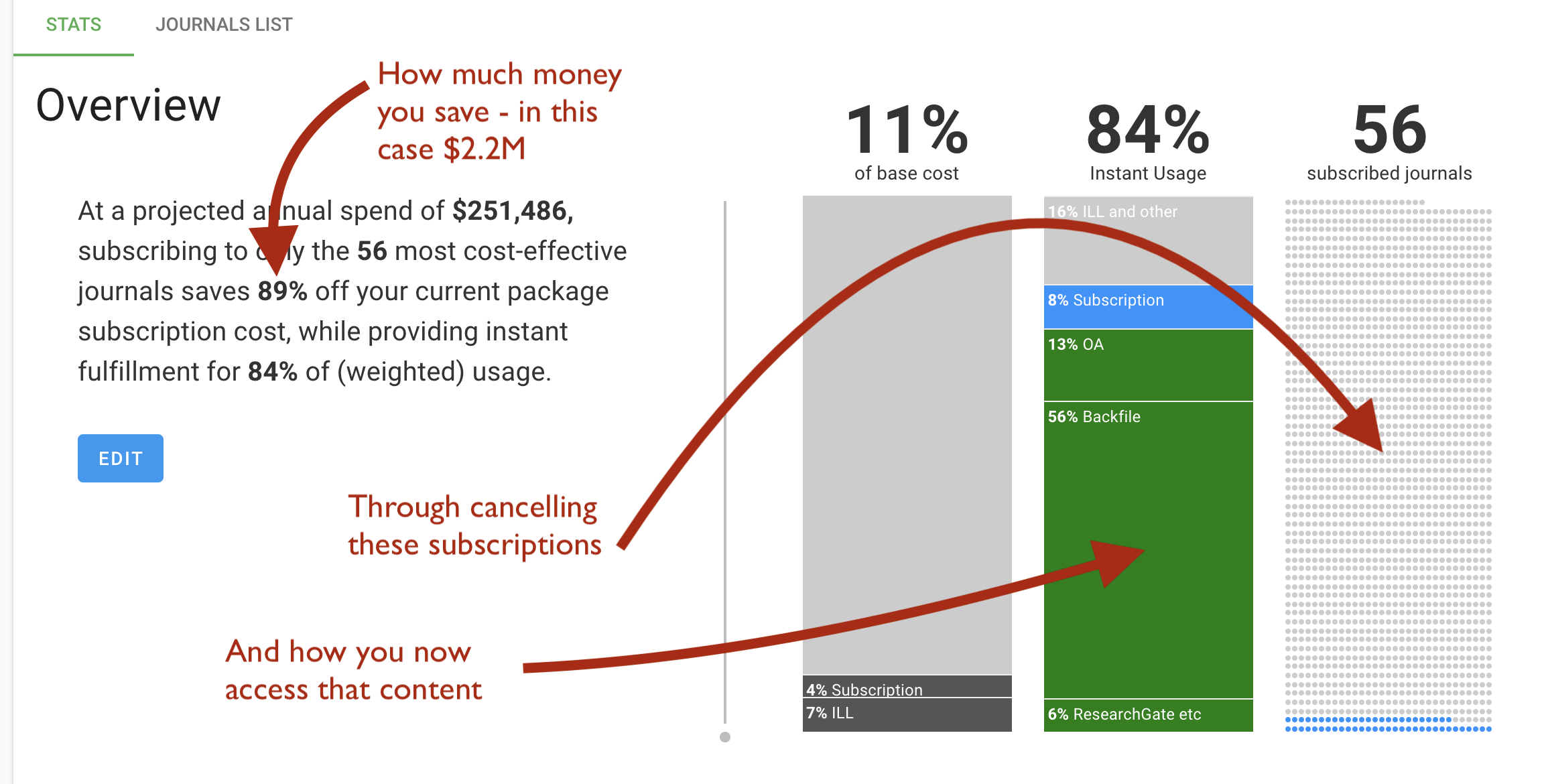
This screenshot shows the view that gives you a rolled up summary of projected cost savings, based on canceling the journals (indicated by the grey dots on the right). The tool allows a ton of modelling to be rolled in to the projection, like % of expected inter library loan, expected cost growth of the current package deal.
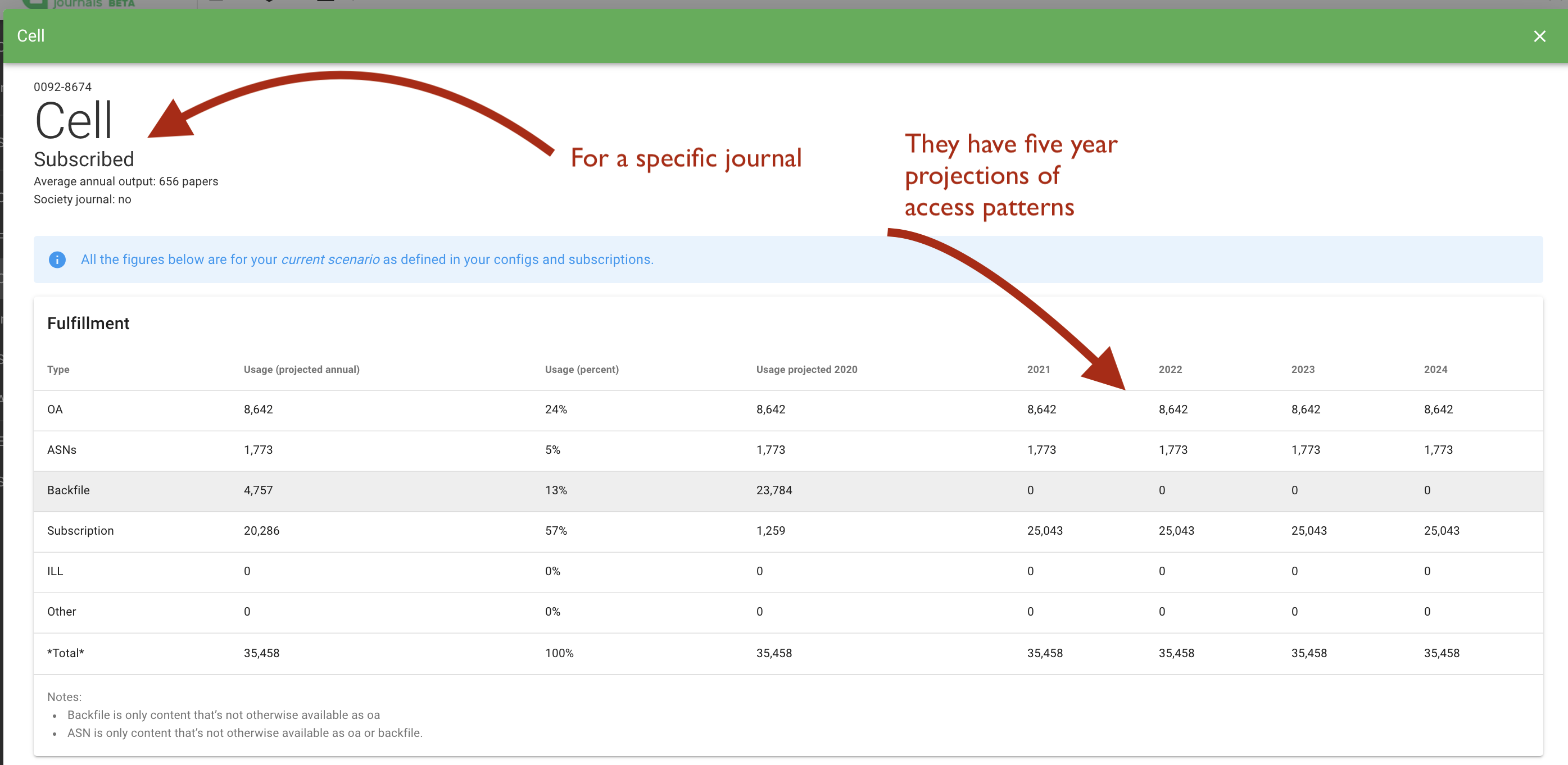
This screenshot shows how they project future expected usage for a single journal.
There are many other aspect of the product, including future citation prediction, based on authors at the given institution.
The bottom line here is that if librarians believe the modelling, then they will have powerful arguments to drive down the cost of their subscriptions.
I think the tool looks powerful, and is the kind of thing that has been within reach of many people to be able to deliver on for some time now, but whether this tool will find a sustainable market I think will depend on two things. 1) if the main use case is for the tool to be used in licence negotiations by libraries then those who make the deals will have to both have confidence in the tool, the data and the modelling, as well as be convinced to change their behaviour based on this information. It will take some early adopters to be willing to talk about their experiences of using this in their negotiations for this tool to be on that becomes a must-have for libraries, and given the length and intricacy involved in content negotiations that lead time might be quite long. 2) if they can’t reach that market quickly enough then reconfiguring the cost and value proposition to sell into an adjacent use case will be critical. There is so much useful information in the tool that a more like that should be possible, but with such aa small team behind the tool even an adjacent shift might be difficult.
I’m bullish on the chances of success of this, and am going to be keeping a close eye on how it progresses.