Textometrica, a tool review
Fri Dec 9, 2016
401 Words
A quick spin with Textometrica
Yesterday I had a good conversation with Simon Lindgren, the creator of textometrica. I decided to try out the tool before chatting to him.
Textometrica encapsulates a process for understanding the relationship and distribution of the occurrence of concepts in a body of plain text. It provides a multi-step online tool for the analysis.
The advantage of using this tool is that you don’t need to be able to do any coding to get to a point where you have some quite interesting analysis of your corpus. One potential downside is that the tool is strongly focussed on the specific workflow that Simon devised. When I talked to him later about this it was clear that he built the tool to scratch a specific itch.
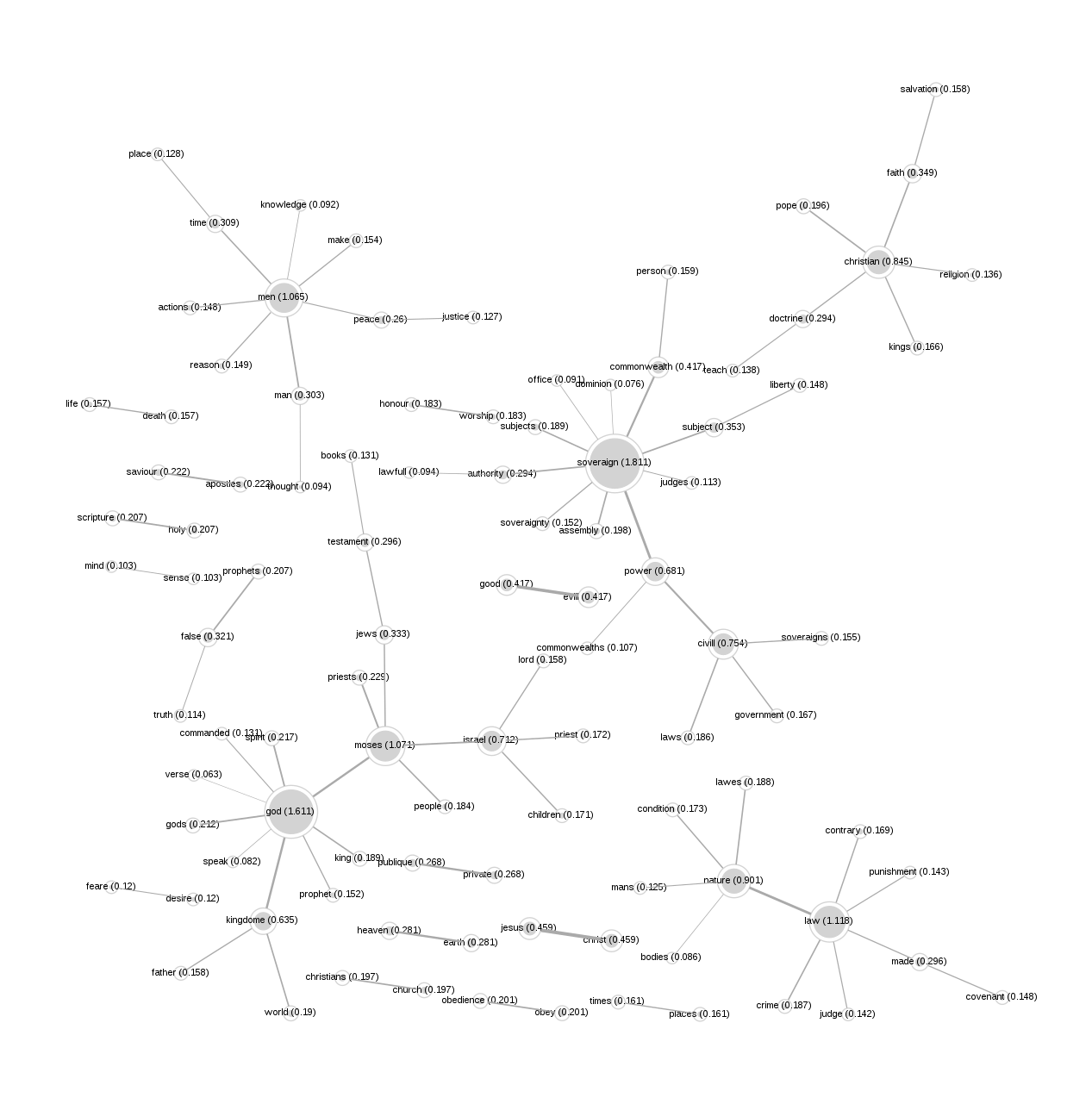
In order to try the tool I needed a corpus to work with. I got a copy of Hobbs’s Leviathan from project Gutenberg, and in a plain text editor I removed the Gutenberg forward and footer.
I started by just trying to upload the file to textometrica, and it looked like I’d made the tool hang. At this point I started looking at the 10 minute video overview of the tool, and I discovered that I need to indicate a text block delimiter within the text. Using the editor I replaced all full stops with the pipe symbol | and re-uploaded, and made much more progress.
If you are interested in exploring the tool I highly recommend working through the video as you get started. The tool is not exactly self-documented, but the video gives a sufficient overview of how to use it.
In under a quarter of an hour I was able to generate a network graph of the largest co-occurring concepts in the Leviathan, and was able to create a public archive of the project.
Each step of the tool has a few custom options, and it seems to me that they were introduced as a result of Simon wanting to refine the process as he developed it. This does provide the ability to do some fine tweaking of your analysis, but at the same time the options are quite opinionated, so you would want the envisaged analysis to be quite close to what you want to do with the tool.
That said, I was able to accomplish a reasonably complex analysis on a reasonably sized corpus very quickly.